人臉檢測江湖的那些事兒

 人類的悲歡并不相通。
人類的悲歡并不相通。
題外話
這是 Face++ Detection Team(R4D)第 3 篇知乎專欄。若是說該專欄的定位是雙標的目的交流,一個比力貼切的詞可能是「窗口」:一方面,我們但愿從論文的出產、研究員的當作長甚至公司的文化空氣等多方面被領會,被熟悉,被熟悉,但愿聯袂配合見證最優檢測算法的研究、立異與落地,沖破認知鴻溝,實現降本增效,為客戶和社會締造最大價值;另一方面,我們也但愿領會讀者的設法,增添與讀者的互動,形當作雙標的目的反饋的正標的目的溝通機制。R4D 后續也會組織線下勾當,加大加深彼此交流。若是你感樂趣,或者想插手,接待聯系 Face++ Detection Team 負責人俞剛 (yugang@megvii.com)。
本次分享的本家兒題是人臉檢測(Face Detection),分享者是曠視科技王劍鋒,來自 Face++ Detection 組。經由過程這篇文章,可以一窺曠視近兩年在該偏向的工作與思慮,并但愿為計較機視覺社區帶來開導,進一步鞭策人臉檢測手藝的研究與落地。人臉檢測是人臉識此外第一站,曠視的盡力本家兒要表現在緊緊環繞人臉檢測范疇頑固而焦點的問題睜開,攻堅克難,功夫花在刀刃上,好比人臉標準的變更及遮擋等,實現速度與精度的雙重漲點。
媒介
人臉檢測的目標是,給心猿意馬肆意圖像,返回此中每張人臉的鴻溝框(Bounding Box)坐標,現實操作上它對通用物體檢測(General Object Detection)有較多借鑒,是通用物體檢測手藝的聚焦和細分。因為人臉檢測是所有人臉闡發算法的前置使命,諸如人臉對齊、人臉建模、人臉識別、人臉驗證 / 認證、頭部姿態跟蹤、面部臉色跟蹤 / 識別、性別 / 春秋識別等等手藝皆以人臉檢測為先導,它的黑白直接影響著人臉闡發的手藝走標的目的和落地,因而在學術界和工業界引起普遍的正視和投入。
現在,跟著深度進修普及,人臉檢測與通用物體檢測已相差無幾,作為二分類使命,其難度也低于通用物體檢測,是以現階段人臉檢測研究更需走差別化路線,從現實應用中羅致營養。
標準轉變是人臉檢測分歧于通用物體檢測的一大問題。通用物體的標準轉變規模一般在十幾倍之內;與之比擬,人臉的標準轉變規模因為攝像頭不竭進級,在 4K 甚至更高分辯率場景中可達數十倍甚至上百倍。面臨這一問題,[1, 2] 給出的謎底是尋找最優標準多次采樣原圖,其素質是優化圖像金字塔(Image Pyramid);[3, 4] 則操縱分歧深度的特征圖順應分歧標準的人臉,其素質是優化特征金子塔(Feature Pyramid);而曠視自立研創的 SFace 方式試著從完全分歧的角度切入這一問題。這是本文第一部門。
和標準轉變一樣,遮擋也是人臉檢測面對的常見挑戰之一。現實場景中的眼鏡、口罩、衣帽、頭盔、首飾以及肢體等皆會遮擋人臉,拉低人臉檢測的精度。對此,[5, 6] 測驗考試晉升神經收集順應遮擋環境的能力,[7] 則將問題轉化為遮擋與非遮擋人臉在標的目的量空間中的距離這一懷抱進修問題。此外,良多深度進修方式練習時輔用的數據加強手藝也在必然水平上提高了收集對遮擋景象的魯棒性;而曠視原創的全新算法 FAN 也是針對人臉遮擋問題而提出。這是本文第二部門。
如上所述,人臉檢測是人臉關頭點、人臉識別等的前置使命,人臉檢測框質量直接影響著整條 Pipeline 的表示,常見人臉檢測數據集的評測指標對鴻溝框質量缺乏存眷;2018 WIDER Challenge Face Detection 初次采用不異于 MS COCO 的評測體例,表白這一狀況已有大幅改善;本文第三部門則將介紹此次角逐奪冠的一些訣竅。
標準轉變: SFace
今朝的人臉檢測方式仍無法很好地應對大規模標準轉變,基于圖像金字塔的方式理論上可籠蓋所有標準,但必需多次采樣原圖,導致大量反復計較;而基于特征金字塔的方式,特征層數不宜加過多,從而限制了模子處置標準規模的上限。是否存在一種方式,圖像只經由過程模子一次,同時又籠蓋到足夠大的標準規模呢?
今朝,單步檢測方式大致可分為兩類:1)Anchor-based 方式,如 SSD[8]、RetinaNet[9] 等;2)Anchor-free 方式,如 DenseBox[10]、UnitBox[11] 等。Anchor-based 方式處置的標準規模雖小,但更精準;Anchor-free 方式籠蓋的標準規模較大,但檢測細小標準的能力低下。一個很是天然的設法就是,兩種方式可以融合進一個模子嗎?抱負很豐滿,實際很骨感,Anchor-based 和 Anchor-free 方式的輸出在定位體例和置信度得分方面差別顯著,直接歸并兩個輸出堅苦很大,具體原因如下:
其一,對于 Anchor-based 方式,ground truth IoU ≥ 0.5 的錨點將被視為正練習樣本。可以發現,正負樣本的界說與鴻溝框回歸成果無關,這就導致 Anchor-based 分支每個錨點輸出的分類置信度本色上暗示的是「錨點框住的區域是人臉」的置信度,而不是「收集展望的回歸框內是人臉」的置信度。故而分類置信度很難評估收集現實的定位精度。對于在營業層將 Classfication Subnet 和 Regression Subnet 分隔的收集,環境將變得更為嚴重。
其二,對于 Anchor-free 方式,收集練習體例近似于方針朋分使命。輸出的特征圖以鴻溝框中間為圓心,半徑與鴻溝框標準當作比例的橢圓區域被界說為正樣本區域,特征圖其它位置(像素)被視為布景。經由過程這種體例,Anchor-free 分支的分類置信度得分本色為「該像素落在人臉上」的置信度,并且該分類置信度與定位的精確度的聯系關系同樣很弱。
總而言之,Anchor-based 方式和 Anchor-free 方式的分類置信度都與回歸定位精度聯系關系甚微,其置信度得分也別離代表著分歧的寄義。是以經由過程分類成果直接歸并兩個分支輸出的鴻溝框是不合理的,而且可能導致檢測機能的急劇下降。
是以,可以將回歸的鴻溝框和 ground truth 鴻溝框之間的 IoU 看成 Classfication Subnet 的 ground truth,這恰是 SFace 所做的工作。
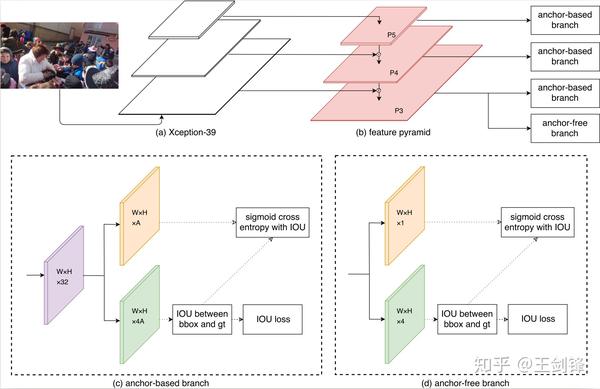 SFace 收集布局
SFace 收集布局具體而言,SFace 設計了 Anchor-based 和 Anchor-free 兩個分支,前者基于 RetinaNet,后者基于 UnitBox;兩個分支都在練習第一步經由過程 Regression Subnet 生當作鴻溝框;接著計較鴻溝框和 ground truth 鴻溝框之間的 IoU;(Anchor-based 分支的)錨點和(Anchor-free 分支的)像素中 IoU ≥ 0.5 的成果將視為 Classfication Subnet 的正樣本,其它則視為負樣本,Classfication Loss 采用 Focal Loss。我們還測驗考試過直接回歸 IoU,然而嘗試成果表白,相較于采用 Sigmoid Cross Entropy 或 Focal Loss,直接回歸 IoU 所得成果方差較大,現實結果欠佳。
Anchor-based 分支和 Anchor-free 分支都利用 IoU Loss 做為 Regression Loss。這種調整有助于同一兩個分支的輸出體例,優化組合成果。經由過程以上批改,兩個分支的分類子收集的本色寄義獲得同一,分類置信度的分布獲得必然水平的彌合,從而 SFace 可有用融合兩個分支的成果。
此外,SFace 必需運行很快才有現實意義,不然大可以選擇做圖像金字塔。為此,基于 Xception,SFace 采用了一個 FLOPs 僅有 39M 的 Backbone,稱之為 Xception-39M,每個 Block 包羅 3 個 SeparableConv 的 Residual Block。Xception-39M 運算量很是小,感觸感染野卻高達 1600+,十分適合處置更高分辯率圖像。
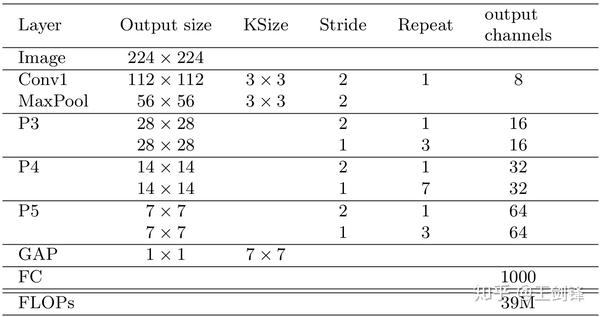 Xception-39M 收集布局
Xception-39M 收集布局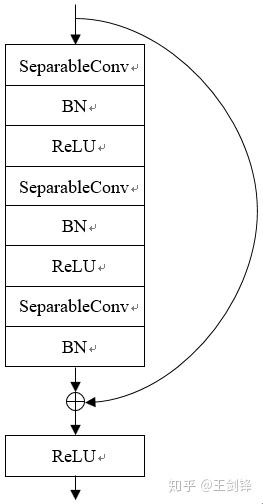 Xception-39M 單一 Block 布局
Xception-39M 單一 Block 布局SFace Backbone 理論計較量只有下表中部門方式的 1/200(這些方式多采用 VGG-16、ResNet-101 等作為 Backbone),且都采用多標準測試;而 SFace 測試全數在單一標準下進行。事實上,SFace 的設計初志恰是只在一個標準下測試即可籠蓋更大規模的標準轉變。
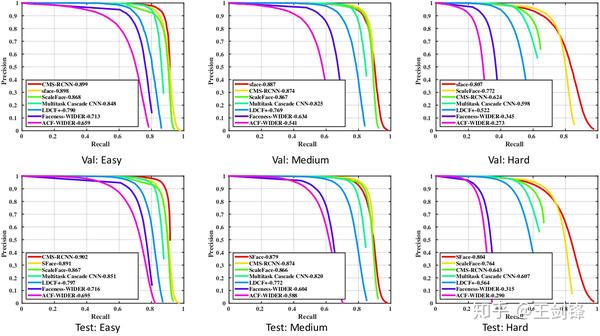 WIDER Face 驗證集和測試集的 PR 曲線
WIDER Face 驗證集和測試集的 PR 曲線消融嘗試證實直接融合 Anchor-based 與 Anchor-free 方式不成行,而 SFace 提出的融合方式是有用的。Anchor-free 分支籠蓋了絕大大都標準(easy set 和 medium set),而 Anchor-based 分支晉升了細小人臉(hard set)的檢測能力。
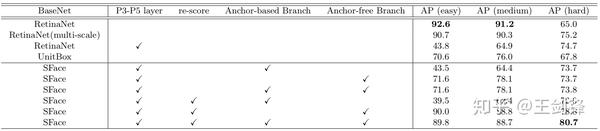 WIDER Face 驗證集的消融嘗試
WIDER Face 驗證集的消融嘗試4K 分辯率下,SFace 運行速度上接近及時,據知這是首個在 4K 分辯率下 WIDER Face hard AP 高于 75 的及時人臉檢測方式。
 SFace 在分歧分辯率下的運行時候(單張 NVIDIA Titan Xp)
SFace 在分歧分辯率下的運行時候(單張 NVIDIA Titan Xp)遮擋:FAN
我們可以從另一個角度考慮遮擋問題。一個物體在清楚可見、無遮擋之時,其特征圖對應區域的響應值較高;若是物體有(部門)遮擋,抱負環境應是只有遮擋區域響應值下降,其余部門不受影響;但現實環境倒是整個物體地點區域的響應值城市降低,進而導致模子 Recall 下降。
解決這個問題大要有兩種思緒:1)盡可能連結住未遮擋區域的響應值,2)把無遮擋區域降低的響應值填補回來;前者較難,后者則相對輕易。一個簡單的做法是讓檢測器進修一個 Spatial-wise Attention,它應在無遮擋區域有更高的響應,然后借助它以某種體例加強原始的特征圖。
那么,若何設計這個 Spatial-wise Attention。最簡單考慮,它該當是一個 Segmentation Mask 或者 Saliency Map。基于 RetinaNet,FAN 選擇增添一個 Segmentation 分支,對于學到的 Score Map,做一個 exp 把取值規模從 [0, 1] 放縮到[1, e],然后乘以原有的特征圖。為簡單起見,Segmentation 分支只是疊加 2 個 Conv3x3,Loss 采用 Sigmoid Cross Entropy。
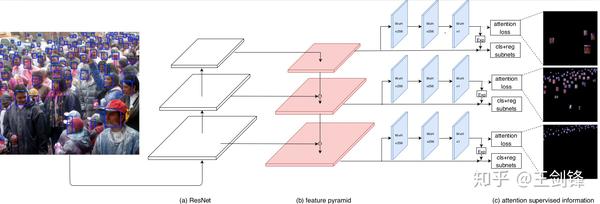 FAN 的分層 Attention
FAN 的分層 Attention這里將面臨的一個問題是,Segmentation 分支的 ground truth 是什么,究竟結果不存在邃密的 Pixel-level 標注。因為人臉圖像近似橢圓,一個先驗信息是鴻溝框區域內幾乎被人臉填滿,布景區域很小;常見的遮擋也不會改變「人臉占有鴻溝框絕大部門區域」這一先驗。基于這一先驗可以直接輸出一個以鴻溝框矩形區域為正樣本、其余區域為負樣本的 Mask,并將其視為一個「有 Noise 的 Segmentation Label」作為現實收集的 ground truth。我們也測驗考試按照該矩形截取一個橢圓作為 Mask,但嘗試成果表白根基沒有區別。
這樣的 ground truth 真能達到結果嗎?經由過程可視化已學到的 Attention Map,發現它確實可以規避開部門遮擋區域,好比一小我拿著話筒講話,Attention Map 會高亮人臉區域,繞開話筒區域。我們相信,若是采用更復雜的手段去清洗 Segmentation Label,現實結果將有更多提高。
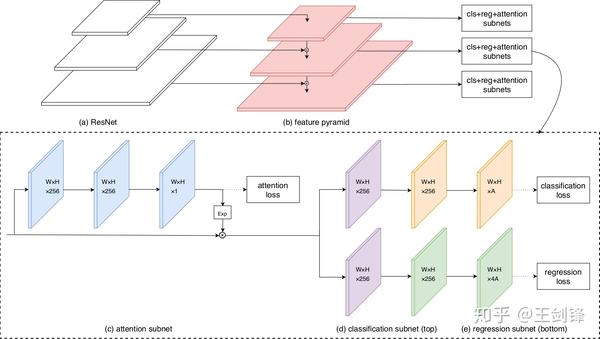 FAN 收集布局
FAN 收集布局FAN 在 WIDER Face 上曾經連結了半年的 state-of-the-arts。因為僅僅驗證方式的可行性,FAN 沒有疊加任何 trick,只在原始的 RetinaNet 上調整錨點框,增添我們的 Spatial Attention,是以 FAN 還有很大的上升空間。
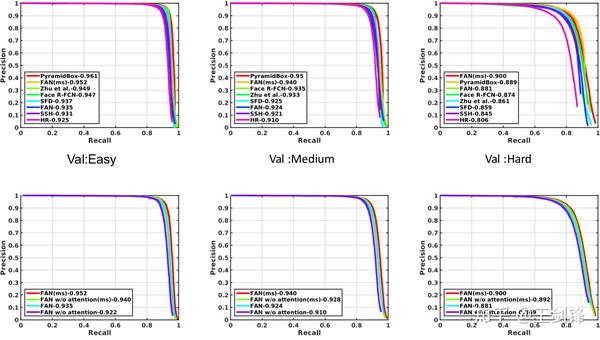 WIDER Face 驗證集的 PR 曲線
WIDER Face 驗證集的 PR 曲線定位精度:2018 WIDER Challenge Face Detection
第三部門介紹一下曠視科技奪魁 上的解決方案。2018 WIDER Challenge 有 3 個 track,曠視參戰了此中的 Face Detection。更多信息請拜見:曠視科技奪獲人工智能頂賽人臉檢測冠軍。
 2018 WIDER Challenge Face Detection 排名
2018 WIDER Challenge Face Detection 排名Face Detection 利用 WIDER Face 數據集原始圖像,可是 Label 做了必然批改。據我們統計,Label 數目稍多于原數據集,導致在不合錯誤模子做任何更改的環境下,利用新 Label 也會比原 Label 漲點(更新:今朝 WIDER Face 官網上已經用 WIDER Challenge Label 籠蓋原 Label,不再存在此問題)。此外,WIDER Challenge 數據集分歧于 WIDER Face 數據集的是,利用了不異于 MS COCO 的 Metrics,這意味著對模子的回歸能力提出了更高的要求。
曠視奪冠的方式仍然基于 RetinaNet。經由過程對比常見 Backbone,我們給出了以下表格的成果。可以發現,更強的 Backbone 并不料味著更好的 Detection 能力。一些 Backbone 分類能力更強,可是供給的特征或者分層特征并不敷好;感觸感染野等對 Detection 至關主要的身分也不合適;對于二分類問題而言也存在過擬合現象。因為嘗試周期等原因,我們最后簡單選擇了 ResNet-50 和 DenseNet-121 繼續后面的嘗試。需要聲明的是,它們在良多環境下都不是最優 Backbone,我們有需要思慮何種 Backbone 提取的特征最適合做檢測。
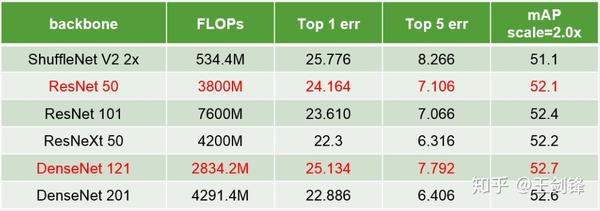 分歧 Backbone 的比力
分歧 Backbone 的比力我們在 Backbone 上應用了 GAP trick,這在上篇知乎專欄(語義朋分江湖的那些事兒從曠視說起)有所介紹。該 trick 同樣合用于 Detection。我們還利用了 Deformable Conv,但其進獻本家兒如果擴大 ResNet 原本不高的感觸感染野。
對于 Head 部門,我們起首將 Smooth L1 Loss 換當作 IoU Loss,這是為賜顧幫襯數據中占比力多的小臉,但現實闡發一下可以發現,在錨點框合適的環境下,IoU Loss 的晉升會很細小。我們對 Head 的本家兒要改動是做一個簡單的 Cascade。Cascade R-CNN[12] 是最早經由過程做 Cascade 晉升模子 Regression 能力的方式,我們但愿將其移植到單步檢測器上。
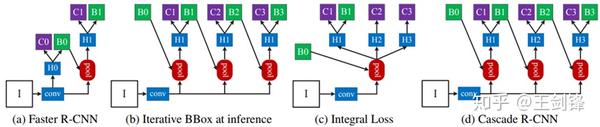 Cascade R-CNN
Cascade R-CNN可以發現,具體做法部門借鑒了 SFace,即把前一個 Stage 的預練習鴻溝框與 ground truth 鴻溝框之間的 IoU 作為下一個 Stage 的 Classification Label;跟著 IoU 逐漸晉升,每個 Stage 的 IoU threshold 也逐漸增大,這與 Cascade R-CNN 很近似。
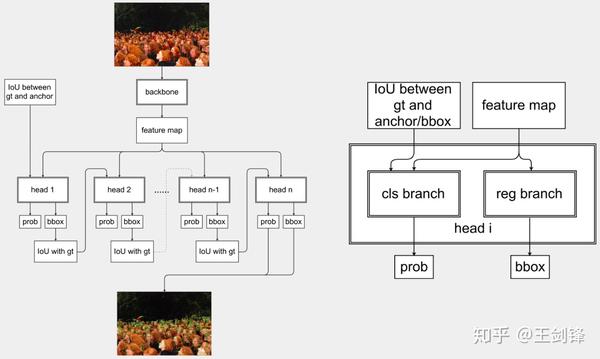 曠視利用的單步檢測 Cascade 方案
曠視利用的單步檢測 Cascade 方案這個 Cascade 方案不難想到,也簡單易行,可是簡直漲點,Inference 時也只需保留最后一個 Stage,不會增添 Inference 當作本;這個方案也有本身的問題,最大的是每個 Stage 在共用統一個特征圖,也共用不變的 anchor,對此已有一些相關論文提出改良,如[13, 14, 15]。
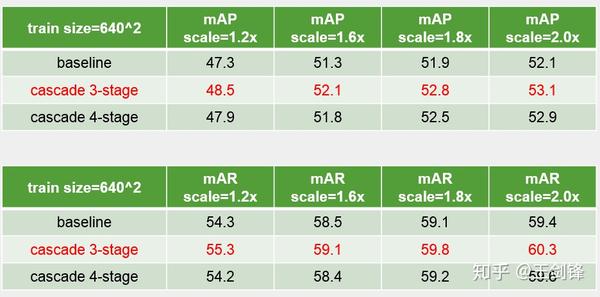 單步檢測 Cascade 的對比嘗試
單步檢測 Cascade 的對比嘗試此外,我們還在 Data Augmentation、Ensemble 等方面做了改良,因為比力 trivial,這里不再贅述。我們曾在 ECCV 2018 Workshop 展示過該方案,更多內容請查閱 slides:
作者簡介
王劍鋒,海說神聊京航空航天大學軟件學院碩士,曠視科技研究院算法研究員,研究偏向人臉檢測、通用物體檢測等;人臉檢測算法 SFace 和 FAN 一作;2018 年加入計較機視覺頂會 ECCV 挑戰賽 WIDER Challenge 獲得人臉檢測(Face Detection)冠軍。
參考文獻:
[1] Hao Z, Liu Y, Qin H, et al. Scale-Aware Face Detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 6186-6195.
[2] Liu Y, Li H, Yan J, et al. Recurrent Scale Approximation for Object Detection in CNN[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 571-579.
[3] Yang S, Xiong Y, Loy C C, et al. Face Detection through Scale-Friendly Deep Convolutional Networks[J]. arXiv preprint arXiv:1706.02863, 2017.
[4] Zhu C, Zheng Y, Luu K, et al. CMS-RCNN: contextual multi-scale region-based CNN for unconstrained face detection[M]//Deep Learning for Biometrics. Springer, Cham, 2017: 57-79.
[5] Opitz M, Waltner G, Poier G, et al. Grid loss: Detecting occluded faces[C]//European conference on computer vision. Springer, Cham, 2016: 386-402.
[6] Chen Y, Song L, He R. Adversarial Occlusion-aware Face Detection[J]. arXiv preprint arXiv:1709.05188, 2017.
[7] Ge S, Li J, Ye Q, et al. Detecting Masked Faces in the Wild With LLE-CNNs[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 2682-2690.
[8] Liu W, Anguelov D, Erhan D, et al. Ssd: Single shot multibox detector[C]//European conference on computer vision. Springer, Cham, 2016: 21-37.
[9] Lin T Y, Goyal P, Girshick R, et al. Focal Loss for Dense Object Detection[C]//Proceedings of the IEEE International Conference on Computer Vision. 2017: 2980-2988.
[10] Huang L, Yang Y, Deng Y, et al. Densebox: Unifying landmark localization with end to end object detection[J]. arXiv preprint arXiv:1509.04874, 2015.
[11] Yu J, Jiang Y, Wang Z, et al. Unitbox: An advanced object detection network[C]//Proceedings of the 2016 ACM on Multimedia Conference. ACM, 2016: 516-520.
[12] Cai Z, Vasconcelos N. Cascade r-cnn: Delving into high quality object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 6154-6162.
[13] Chen X, Yu J, Kong S, et al. Towards Real-Time Accurate Object Detection in Both Images and Videos Based on Dual Refinement[J]. arXiv preprint arXiv:1807.08638, 2018.
[14] Wang J, Chen K, Yang S, et al. Region proposal by guided anchoring[J]. arXiv preprint arXiv:1901.03278, 2019.
[15] Kong T, Sun F, Liu H, et al. Consistent Optimization for Single-Shot Object Detection[J]. arXiv preprint arXiv:1901.06563, 2019.
- 發表于 2019-03-03 21:53
- 閱讀 ( 914 )
- 分類:其他類型
0 篇文章
作家榜 ?
-
 xiaonan123
189 文章
xiaonan123
189 文章
-
 湯依妹兒
97 文章
湯依妹兒
97 文章
-
 luogf229
46 文章
luogf229
46 文章
-
 jy02406749
45 文章
jy02406749
45 文章
-
 小凡
34 文章
小凡
34 文章
-
 Daisy萌
32 文章
Daisy萌
32 文章
-
 我的QQ3117863681
24 文章
我的QQ3117863681
24 文章
-
 華志健
23 文章
華志健
23 文章