如何用python進行中文分詞
東西/原料
- python 3.8.2(其他版本也可以)
- pycharm 2020.01(其他版本也可以)
方式/步調
- 1
在本次教程中,我們采用pycharm進行編程。起首領會一下jieba庫,jieba庫是優異的中文分詞第三方庫。
jeiba庫分詞的道理:jieba分詞依靠中文詞庫,操縱一個中文詞庫,確定中文字符之間的聯系關系概率,中文字符間概率大的構成詞組,形當作分詞成果。
- 2
安裝jieba庫:
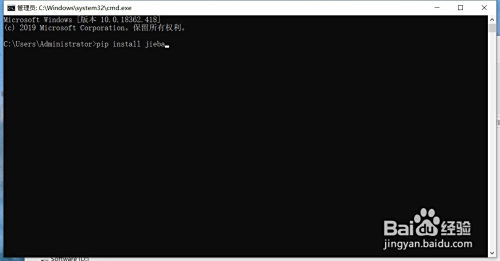
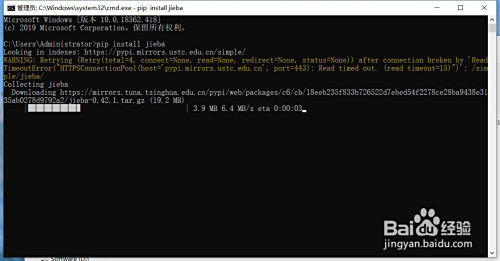
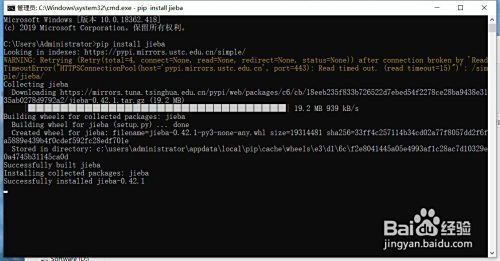
在桌面摁下“win”+“r”,輸入cmd,接著輸入“pip install jieba”,期待號令交運行完當作,當呈現“successful”就申明jieba庫已經安裝當作功了。
- 3
jieba庫有三種分詞模式,切確模式、全模式、搜刮引擎模式。
切確模式:把文本切確地且分隔,不存在冗余單詞。
全模式:把文本中所有可能的詞語都掃描出來,詞與詞之間存在反復部門,有冗余。
搜刮引擎模式:在切確模式根本上,對長詞再次切分。
- 4
jieba庫常用函數:
1、jieba.lcut(s) 切確模式,返回一個列表類型的分詞成果
2、jieba.lcut(s, cut_all=True) 全模式,返回一個列表類型的分詞成果,有冗余
3、jeiba.lcut_for_search(s) 搜刮引擎模式,返回一個列表類型的分詞成果,存在冗余
(其他函數操作可以參照官方文檔)
- 5
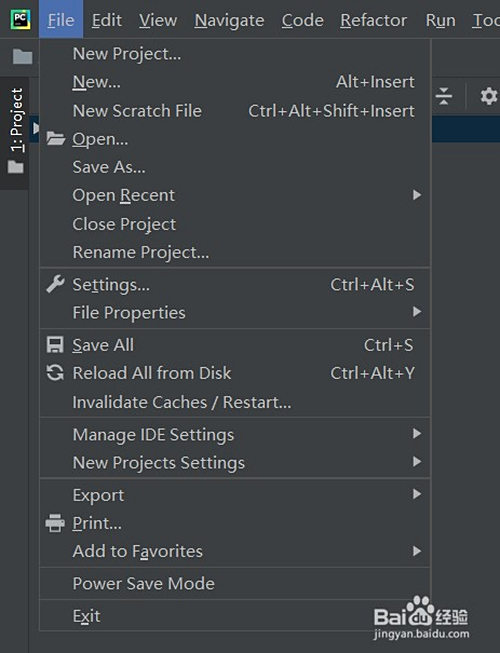
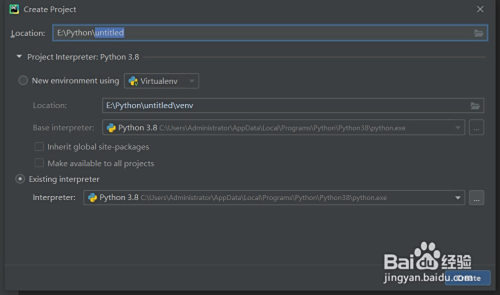
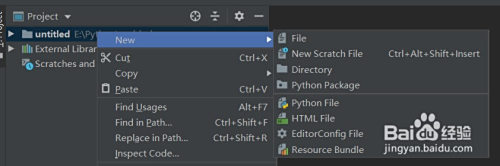
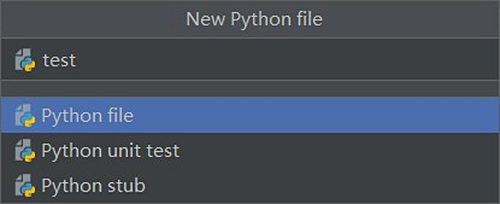
打開pycharm,點擊左上角“File”-“New Project”新建一個項目(圖1),選擇肆意目次,選擇python 3.8詮釋器,點擊“cerate”,在project處右鍵點擊“New”-“Python File”,肆意取一個名字回車
- 6
在新建的py文件中輸入:
import jieba
txt = "把文本切確地分隔,不存在冗余單詞"
# 切確模式
words_lcut = jieba.lcut(txt)
print(words_lcut)
# 全模式
words_lcut_all = jieba.lcut(txt, cut_all=True)
print(words_lcut_all)
# 搜刮引擎模式
words_lcut_search = jieba.lcut_for_search(txt)
print(words_lcut_search)代碼即可實現對字符串txt的分詞
END
注重事項
- 文章利用pycharm進行編程,也可以利用IDLE進行編程。
- jieba庫在安裝時,若頻仍呈現timeout,可以過段時候再試,或者運行 pip install jieba -i https://pypi.tuna.tsinghua.edu.cn/simple/ 利用清華源進行安裝
- 官網文檔請在pypi搜刮jieba
- 發表于 2020-04-24 19:00
- 閱讀 ( 2372 )
- 分類:其他類型
0 篇文章
作家榜 ?
-
 xiaonan123
189 文章
xiaonan123
189 文章
-
 湯依妹兒
97 文章
湯依妹兒
97 文章
-
 luogf229
46 文章
luogf229
46 文章
-
 jy02406749
45 文章
jy02406749
45 文章
-
 小凡
34 文章
小凡
34 文章
-
 Daisy萌
32 文章
Daisy萌
32 文章
-
 我的QQ3117863681
24 文章
我的QQ3117863681
24 文章
-
 華志健
23 文章
華志健
23 文章